
我们在多云解决方案应该旨在解决的“数据引力”痛点的背景下定义了多云,并强调了多云和多云数据架构之间的区别。提醒一下,在那篇文章中,我们将数据引力定义为一种特别痛苦的云供应商锁定:
数据引力是一种现象,即组织收集的数据越多,将数据移动到新位置或系统就越困难。在云的上下文中,随着数据在云中积累,它会吸引更多的应用程序、服务和用户到同一个云中。这种自我强化的“引力”使得将数据提供给其他云中的应用程序和服务变得越来越具有挑战性。因此,遭受数据引力困扰的组织将发现自己被锁定在特定技术或供应商中,从而限制了他们的灵活性、敏捷性和管理云供应商成本的能力。
建立背景后,我们将把注意力转向帮助您回答以下问题:“我的数据架构是多云还是多云?多云和多云部署模型之间最重要的区别在于解决方案是使用应用程序优先还是数据优先设计原则进行架构。
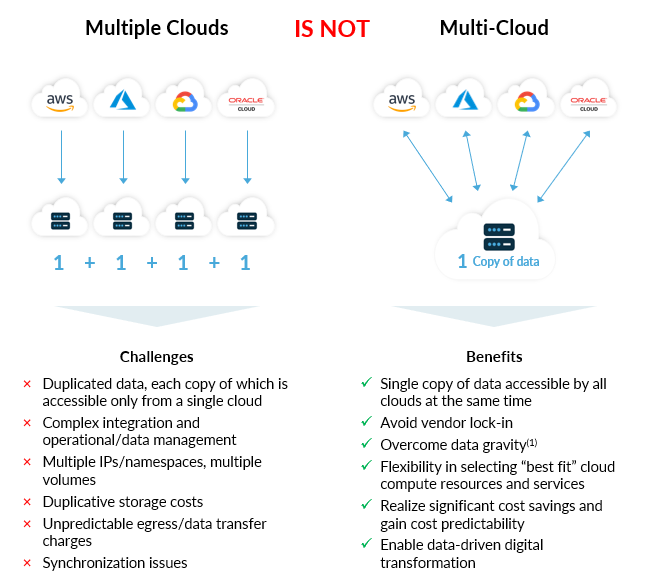
多云部署首先要决定在何处运行应用程序,以及使用哪些本机和第三方云服务。应用程序优先决策总是导致数据被“分发”到应用程序和服务运行的位置/云中,每个数据集都在孤岛中运行,孤岛具有自己的数据引力“量”。
相比之下,数据优先体系结构首先评估启用应用程序所需的数据以及组织使用的所有数据服务。有了这种理解,决策就可以转向“放置”的位置以及如何管理数据。该决策应旨在实现三个目标:
在传统的以应用程序为中心的架构中,这些目标是不一致的;并且在很大程度上,考虑到应用程序之后的数据范式,存在明确的冲突。但在多云设计中,可以通过将数据放置在与云无关的第三方提供的数据存储中具有多个云提供商的区域来实现这些目标的协调。
这种数据优先的云架构方法的自然结果是,从性价比的角度来看,可以非常灵活地确定每个应用程序可以在哪个云中最佳运行。
本着图片胜过千言万语的精神,下图反映了源于应用程序优先设计原则的多云设计,与来自数据优先设计原则的多云设计形成鲜明对比。
为了更好地区分多云和多云设计原则,以下是几个值得考虑的问题:
如果您对上述问题的回答倾向于“是”,则您可能在云部署中依赖于应用程序优先的设计原则。巧合的是,您很可能会遇到源于数据引力的痛点,包括需要在本地和云环境中移动和复制数据。
如果您的组织遇到与多个云设计原则相关的痛点,您可能会受益于转向数据优先设计原则,该原则利用真正的多云数据存储解决方案。真正的多云解决方案将使您的组织能够通过同时向多个公共云中的应用程序和服务呈现数据的一个副本来摆脱数据引力;加速组织的数据驱动型转型,并使您能够根据应用程序级性价比考虑因素优化有关每个工作负载运行位置的决策。

 网站资讯
网站资讯 渠道合作
渠道合作 解决方案
解决方案 更多服务
更多服务


